NBA 선수 Stat 데이터분석 pt2- Clustering을 해보자
Category: Technology
<NBA 선수 Stat 데이터 분석 - Clustering>















<NBA 선수 Stat 데이터 분석 - Clustering>
지난번의 게시글 에서 다뤘던 NBA 선수 데이터를 다시 한번 가져와봤다. 지난번엔 득점, 파울, 그리고 어시스트의 세 가지를 Feature(특성)으로 해서 20,000명이 넘는 선수의 데이터의 회귀분석을 시도했다. 그렇지만 워낙 분산이 크고, 세 가지 특성만을 가지고 회귀분석을 하기에는 정확도가 높은 편은 아니었다.
이번에는 '포지션'을 한번 고려해서 Clustering과 Classifying을 해보면 어떨까 하는 생각이 들었다. 농구 경기에서는 포지션별로 조금씩 역할이 다르다. 세 가지로 크게 나눌 때 주로 후방에서 패스를 돌리고, 외곽 공격이나 전체적인 공의 운반을 하게되는 가드, 반면 전방에 위치하여 몸싸움을 담당하고 링(골대)와 가까운 곳으로 뛰어드는 포워드, 그리고 보통 가장 큰 덩치를 가지고 골 밑을 지키는 센터는 현대 농구에 들어서는 점점 포지션의 경계가 (예전에비해) 흐려지고 한 선수가 여러 포지션을 겸하는 일도 늘어나고 있기는 하지만 분명 플레이스타일과 역할에 차이가 있다. 세 포지션 안에서도 세부적인 역할에 따라 역할이 나뉘기도 한다. (ex: 슈팅을 중점적으로 하는 가드는 슈팅 가드, 경기의 운영과 볼의 운반, 패스와 공격 작전을 주도하는 가드는 포인트 가드라고 한다.) 그러다보니 (맞건 틀리건) 일반적으로 가드가 센터에 비해 슛을 잘한다던지, 가드에 비해 포워드나 센터가 리바운드에 강점을 보인다던지, 가드는 몸싸움에 약하다던지 하는 통념이 자리잡게되었다.
그렇다면, 선수들의 특성 (Stat)을 통해 포지션을 구별해낼 수 있을까? 또 만일 선수들의 특성을 통해 이상적인 포지션을 예측하는 모델을 만들어낸다면, 능력치에 맞지 않는 포지션을 맡아 뛰고있는 선수들이 누구인지 알 수 있지 않을까? 또한 앞으로 신인 선수를 발굴할 때 이 선수가 가장 기량을 잘 펼 수 있는 포지션이 무엇일지 시행착오를 최소화하며 알아낼 수 있지 않을까? 어쩌면 영화 머니볼이 우리에게 시사했던 것처럼 스포츠계에도 '직관'과 함께 '데이터'를 활용하는 것의 중요성이 널리 알려지고 있으며 많은 스포츠 팀들이 실제로 데이터를 많이 활용한다고 한다. 따라서 어쩌면 이미 이러한 데이터정보를 활용하는 구단이 이미 존재하는지도 모르겠다.
어쨌거나 그와 별개로, 이 NBA 선수 Stat 데이터를 바탕으로 Clustering/Classification을 진행해보기로 했다. Clustering과 Classification 알고리즘에 대한 설명은 이 게시물에서 자세히 다루었다. 먼저 Clustering의 경우에는, Label, 즉 포지션을 따로 떼어놓고 선수들의 특성들만을 가지고 유사한 그룹으로 묶으려 한다. 그다음 원래의 포지션과 얼마나 유사성을 띄는지를 살펴보고자 한다.
다음으로 Classification은, 전체 데이터를 Training Data와 Test Data로 나누어 포지션을 Label로 해서 모델을 학습시킨 뒤, 이 모델을 이용해 test data의 포지션을 예측해볼 것이다.
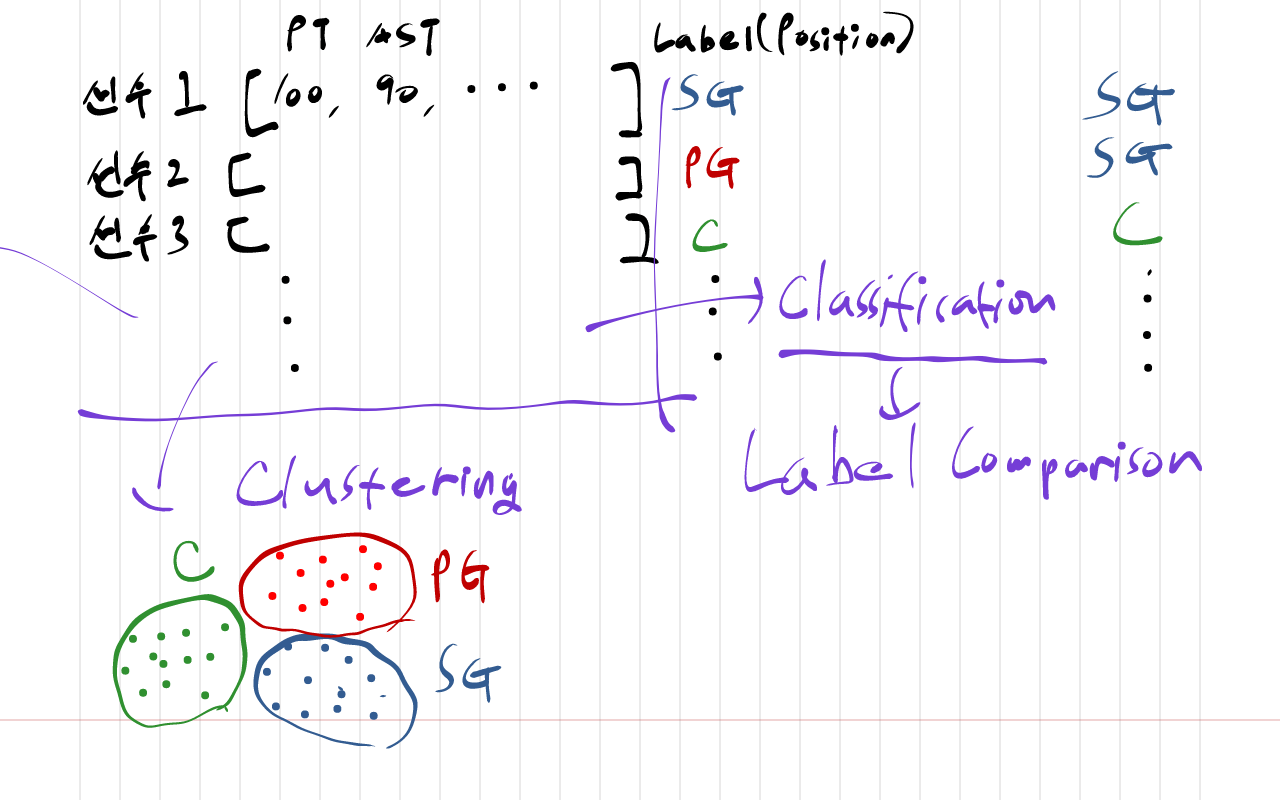
분량 관계상 이번 게시글에서는 Clustering에 대해서만 먼저 다루고, 그 다음 Classification에 대해 다뤄볼 것이다.
Clustering을 하기 전에
먼저 데이터를 좀 살펴보고, 본격적인 Clustering을 해보자. 일단, 나는 이 데이터의 경우 Classifying에 비해 Clustering의 정확도가 더 낮을 것으로 예상했다. 이유는 첫 번째로, 단지 Label 없이 feature만을 가지고 유사한 그룹으로 묶어서 구분짓기에는 포지션간의 구별이 명확하지는 않다. 대부분의 feature는 선수의 경기 기록과 관련된 숫자 데이터이다. (파울, 어시스트, 득점, 경기를 뛴 시간 등). 모든 선수들이 같은 규칙 속에서 유사한 행동반경을 가지도록 제한받고, 같은 목표를 가지고 움직인다. feature만을 clustering을 하게 되면 '포지션'보다는 실력이나 득점력, 혹은 플레이스타일과 같은 다른 공통점을 기준으로 묶일 가능성이 더 크지 않을까 싶다. 두 번째 이유는, Position간의 경계가 모호하기 때문에 같은 포지션의 선수들이라도 성향이 전혀 다를 수 있고, 또 한 선수가 여러 포지션의 성향을 띄게될 수도 있다. 이와같은 이유로 이 데이터를 통해 '포지션'을 구별해내기 위해서는 정해진 답(Lablel), 즉 포지션을 함께 학습시켜야 한다고 생각했다.
그래도 일단 결과가 궁금하니 Clustrering도 진행해보기로 하자. 먼저 이번에 사용할 Clustering 알고리즘은 지난번에 사용했던 KMeans clustering 알고리즘을 사용하겠다. 대신, sklearn패키지에서 미리 정의된 KMeans 함수를 그대로 쓰지 않고, tensorflow를 이용해 KMeans clustering 하는 함수를 정의해보겠다.
자, 이제 어떤식으로 Clustering이 되는지를 살펴보기 위해 임의의 데이터를 생성해 clustering해보자. (이 KMeans clustering의 코드는 이 블로그를 참고하였으며, 원문은 스페인 카탈루냐 공과대학의 Jordi Torres 교수가 텐서플로우를 소개하는 책 First Contack with TensorFlow이다.)
생성된 데이터는 다음과 같으며 클러스터링을 진행하면:


Clustering을 하기 전에
먼저 데이터를 좀 살펴보고, 본격적인 Clustering을 해보자. 일단, 나는 이 데이터의 경우 Classifying에 비해 Clustering의 정확도가 더 낮을 것으로 예상했다. 이유는 첫 번째로, 단지 Label 없이 feature만을 가지고 유사한 그룹으로 묶어서 구분짓기에는 포지션간의 구별이 명확하지는 않다. 대부분의 feature는 선수의 경기 기록과 관련된 숫자 데이터이다. (파울, 어시스트, 득점, 경기를 뛴 시간 등). 모든 선수들이 같은 규칙 속에서 유사한 행동반경을 가지도록 제한받고, 같은 목표를 가지고 움직인다. feature만을 clustering을 하게 되면 '포지션'보다는 실력이나 득점력, 혹은 플레이스타일과 같은 다른 공통점을 기준으로 묶일 가능성이 더 크지 않을까 싶다. 두 번째 이유는, Position간의 경계가 모호하기 때문에 같은 포지션의 선수들이라도 성향이 전혀 다를 수 있고, 또 한 선수가 여러 포지션의 성향을 띄게될 수도 있다. 이와같은 이유로 이 데이터를 통해 '포지션'을 구별해내기 위해서는 정해진 답(Lablel), 즉 포지션을 함께 학습시켜야 한다고 생각했다.
그래도 일단 결과가 궁금하니 Clustrering도 진행해보기로 하자. 먼저 이번에 사용할 Clustering 알고리즘은 지난번에 사용했던 KMeans clustering 알고리즘을 사용하겠다. 대신, sklearn패키지에서 미리 정의된 KMeans 함수를 그대로 쓰지 않고, tensorflow를 이용해 KMeans clustering 하는 함수를 정의해보겠다.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def kmeans_tensor(K , Data):
vectors = tf.constant(Data)
# [2000, 2] 모양 텐서
k=K
centroides = tf.Variable(tf.slice(tf.random_shuffle(vectors), [0,0], [k, -1]))
#data텐서를 섞어서 (2000개가 섞임)), slice로 4개를 뽑음
#[0,0]부터 [4, -1] (즉 4 row 전체까지)
#Centroid는 [4, 2]모양 텐서
expanded_vectors = tf.expand_dims(vectors, 0)
#[2000, 2모양인 vector의 차원을 추가. [1, 2000, 2 모양]]
expanded_centroides = tf.expand_dims(centroides, 1)
#이제 [4, 1, 2]모양
#[[[[1], [2]], [[3], [4]], ....[[3999], [4000]]]]
#
#[[[[1], [2]]],
#[[[3], [4],]],
#[[[5], [6]]],
#[[[7], [8]]]]
assignments = tf.argmin(tf.reduce_sum(tf.square(tf.subtract(expanded_vectors, expanded_centroides)), 2))
means = tf.concat([tf.reduce_mean(tf.gather(vectors, tf.reshape(tf.where(tf.equal(assignments, c)), [1, -1])), reduction_indices = [1])for c in range(k)], 0)
update_centroides = tf.assign(centroides, means)
init_op = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init_op)
for step in range(1000):
_, centroid_values, assignment_values = sess.run([update_centroides, centroides, assignments])
print ("Centroids are:", centroid_values, "Assigned values are:", assignment_values)
dt = {"x": [], "y": [], "cluster": []}
for i in range(len(assignment_values)):
dt["x"].append(Data[i][0])
dt["y"].append(Data[i][1])
dt["cluster"].append(assignment_values[i])
dt=pd.DataFrame(dt)
sns.lmplot("x", "y", data = dt, fit_reg = False, size = 6, hue = "cluster", \
legend = True)
plt.show()
자, 이제 어떤식으로 Clustering이 되는지를 살펴보기 위해 임의의 데이터를 생성해 clustering해보자. (이 KMeans clustering의 코드는 이 블로그를 참고하였으며, 원문은 스페인 카탈루냐 공과대학의 Jordi Torres 교수가 텐서플로우를 소개하는 책 First Contack with TensorFlow이다.)
num_points = 2000
data = []
for i in range(num_points):
if np.random.random() > 0.5:
data.append([np.random.normal(0.0, 2), np.random.normal(0.0, 2)])
else: data.append([np.random.normal(5, 1), np.random.normal(3, 1)])
df = pd.DataFrame({"x": [v[0] for v in data], "y":[v[1] for v in data]})
sns.lmplot("x", "y", data = df, fit_reg = False, size = 6)
plt.show()
print(kmeans_tensor(4, data))
생성된 데이터는 다음과 같으며 클러스터링을 진행하면:


이렇게 4개의 Cluster로 묶이게 된다
그럼 이제 우리의 농구선수 데이터를 한번 살펴보자. 일단 이 데이터에는 총 7가지로 포지션이 표기되어있다: G(가드), SG (슈팅가드), SF(스몰포워드), F(포워드), PG(포인트가드), PF(파워포워드), C(센터)
여기서 두 가지 문제점이 발생한다. 첫 번째는, 한 선수가 두 포지션을 겸하는 경우가 있다보니 포지션의 경우의 수가 너무 많아졌다:
{'G-F', 'PF-C', 'C-SF', 'F-C', 'SF-SG', 'SG-SF', 'G', 'SG-PG', 'F', 'PF', 'C-PF', 'PG-SG', 'SF-PG', 'C-F', 'SF', 'PG', 'F-G', 'C', 'SG', 'SG-PF', 'PG-SF', 'SF-PF', 'PF-SF'}
이렇게 포지션이 너무 많은 그룹으로 나누어지게 되면, 특성에 따라 선수들이 크게 구별되지 않기때문에 클러스터링의 의미가 없고, 클러스터링을 하기도 어려워진다. 따로 확인해본결과 다행히 둘 이상의 포지션으로 표기된 선수는 총 2만개가 넘는 데이터 중 200여개 남짓으로 겨우 1%밖에 되지 않았다. 따라서, 'SF-SG'와 같이 듀얼 포지션으로 표기된 경우에는 두 번째 포지션을 떼어버리고 첫 번째 포지션으로 통일하는 작업을 수행했다. '이렇게 되면 두 번째 포지션에 따른 특성을 반영하지 못하는 문제가 생기지 않는가?' 라고 생각할 수도 있겠지만 과감히 버리는 선택은 한 이유는 첫째, 빅 데이터에서는 자잘한 들쭉날쭉함이 문제가 되지 않는다. 두 번째로, 한 선수가 두 포지션을 겸하는 대부분의 경우, 두 포지션은 성격이 유사한 포지션일 확률히 극히 높다. 예를들어, 가드의 성향을 가진 키는 작지만 드리블이 재빠르고 슛 결정력이 좋은 포인트가드인 선수가 슈팅가드를 겸할 경우는 많을 수 있으나, 이 선수가 센터에 서게 될 확률은 극히 드물다. 이 역시도 데이터를 통해 직접 확인해보았다면 좋았겠지만 일단은 직관에게 맡기고 다음 작업으로 넘어가도록 하겠다.
다음은 듀얼 포지션을 덜어내고, 7가지의 포시션으로 통일하는 과정이다.
New_Pos = []
for i in df[["Pos"]].values:
if "-" in i[0]:
ind = i[0].index("-")
New_Pos.append(i[0][:ind])
else:
New_Pos.append(i[0])
Simple_Pos = []
for i in New_Pos:
if i == "G" or i=="PG" or i=="SG":
Simple_Pos.append("Guard")
elif i == "F" or i=="PF" or i=="SF":
Simple_Pos.append("Forward")
else:
Simple_Pos.append("Center")
New_Pos = Simple_Pos
df["New_Pos"] = np.array(New_Pos)
del df["Pos"]
sns.pairplot(data = df, hue = "New_Pos")
plt.show()
positions = list(set([i[0] for i in df[["New_Pos"]].values]))
positions = sorted(positions) #order 섞이는것 방지
colors = ['blue', 'yellow', 'red']
이제 이를 바탕으로 데이터의 분포를 그려보겠다. 총 3개의 변수를 가졌으니 2d평면에 전개해 그린 그래프와, 3d좌표계에 그린 그래프를 모두 보이도록 하겠다.
sns.pairplot(data = df, hue = "New_Pos")
plt.show()
def plot3d(X, y, dg=30):
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for position in positions:
PF_=[]
PTS_=[]
AST_=[]
for j in range(len(y)):
if y[:, 0][j]==position:
PF_.append(X[:, 0][j])
PTS_.append(X[:, 1][j])
AST_.append(X[:, 2][j])
ax.scatter(PF_, PTS_, AST_, c = colors[positions.index(position)])
plt.legend(positions)
ax.view_init(dg)
plt.show()
for i in range(0, 3):
print (plot3d(X, y, i*30))
3차원 좌표의 그래프는 위쪽 방향으로 30도씩 회전하며 보여준 모습을 총 3개 출력했다.







적어도 포지션끼리 뭉쳐있는 모양을 보여주긴 하지만, 여기서 한 가지를 간과했음을 깨달았다. 7개의 포지션 분포 역시 너무 세세하다. 특히, 같은 계열의 포지션 - 예컨데 가드와 슈팅가드, 스몰포워드와 포워드- 의 경우 상당히 구분없이 뒤섞여있는 모습을 보여준다. 그래서 더 의미있는 구별을 짓기 위해 포지션을 큰 구분으로 나누어 가드, 센터, 포워드의 세 가지로 나누기로 했다. 위의 코드에서 potision을 나누는 부분을 조금 수정해보았다.
New_Pos = []
for i in df[["Pos"]].values:
if "-" in i[0]:
ind = i[0].index("-")
New_Pos.append(i[0][:ind])
else:
New_Pos.append(i[0])
Simple_Pos = []
for i in New_Pos:
if i == "G" or i=="PG" or i=="SG":
Simple_Pos.append("Guard")
elif i == "F" or i=="PF" or i=="SF":
Simple_Pos.append("Forward")
else:
Simple_Pos.append("Center")
New_Pos = Simple_Pos
df["New_Pos"] = np.array(New_Pos)
del df["Pos"]
sns.pairplot(data = df, hue = "New_Pos")
plt.show()




이제 좀더 깔끔하게 세 가지로 포지션이 나뉘었다. 이렇게 설명하면 웃길지도 모르겠지만 마치 홍합(...)과 같은 모양을 띄고, z축에 '어시스트'를 놓았을때 아래에서부터 센터, 포워드, 가드 순으로 층을 이루어 쌓인 형태임을 볼 수 있다. x, y축의 파울, 득점보다도 어시스트가 세 포지션을 더 극명히 나눠주는듯한 모양을 보이는데, 상대적으로 가드가 높은 어시스트율을, 센터가 낮은 어시스트율을 보인다.
Clustering, 그리고 데이터 비교
자 이제 위의 3가지 포지션 구분을 바탕으로 클러스터링을 하고, 실제 포지션 분포와 유사하게 그룹지어였는지를 한번 확인해보자. print (kmeans_tensor(3, X)) 코드를 실행시켜 나온 그래프는 다음과 같다:

여기서 클러스터링의 맹점 한 가지는, '비지도학습'이기때문에 원래의 레이블과 맞춰보기에는 용도가 적절하지 않다는 점이다. 이 경우에도 포지션을 세 가지 그룹으로 - 0, 1, 2라는 레이블을 가지고 나누기는 했지만 어떤 그룹이 각각 센터, 가드, 포워드를 나타내는지는 알 길이 없다. 이것이 바로 지도학습과 비지도학습의 용도가 확실히 나뉘는 이유 중 하나이다.
어찌됬건 Cluster된 데이터를 한번 살펴보자. 기본적으로 어시스트를 기준축으로 할 때 세 포지션이 층을 이루는 구조가 똑같이 나타난다! Clustering 알고리즘이 여러가지 feature를 통해 세 포지션 그룹의 대략적인 큰그림을 잘 잡아냈다고 봐도 될 듯 하다. 아마 어시스트를 기준으로 가장 아래쪽에 깔려있는 녹색 (1번)이 센터, 파란색 (0번)이 가드, 빨간색(2번)이 포워드에 해당하는 그룹이 될 것이다. 클러스터링은 비지도학습이기 때문에 정확도를 어떻게 계산해야 할지 참 난감했는데, 만일 계산할 수 있더라도 데이터 포인트 하나하나가 올바르게 clustering되었는지 수치를 계산한다면 좋은 수치가 나올 것 같지는 않다. 전체적인 feature를 분석해 세 포지션의 특성은 잡아냈더라도, (글의 앞부분에서 두 가지 이유를 이야기했듯) feature만으로 레이블 없이 세세한 포지션을 구분하기엔 포지션간의 구별이 충분히 명확하지 않다.
---
한번에 너무 많은것을 다루면 분량이 길고 지루해지니 Classification에 대해서는 다음 포스트에서 다루도록 하겠다.





댓글
댓글 쓰기